
Moving to a new Dedicated Server, Hosting my Own Metrics
it's a project all to itself

So I’ve been away for a bit. Life stuff! Christmas with all of its difficulty and complexity came and went, my extremely adorable and personable cat got very sick and might not make it, and I started a significant subproject.

The significant project? Moving all of my personal and private projects to a new server - well, set of servers.
The big reasons for this - well, there are a few, but a lot of them come down to cost.
For one thing, especially running the same dedicated hardware for 5 solid years, I am now officially paying too much for my old dedicated server. I can get a significantly cheaper one from Hetzner for a fraction of the price. I mean, it’s Hetzner, so it’ll be running out of Finland🇫🇮, but, well, that’s a small price to pay for… a small price, to pay. With modern CDNs 90% of a website lives 10ms away from everyone anyways. Admittedly, the 150ms ping is something that I can FEEL while I’m ssh-ed into a server that’s a continent away from me, but - well, directly ssh-ing into a server isn’t how I administer my boxes nowadays anyways. This is a job for automation.
And, for automation, most of the job is falling to my old friend ansible. I’d… honestly really hoped that something better would exist by now. It still works like complete garbage on Windows, which half of my computers is, but… idk, maybe I’ll finally engage with WSL2 or just… run it from a relay server in Finland or something.
Anyways, one of the big goals of this project is to move to fully self-managed logging and metrics.
The groovelet mythology actually has daemons for this, the fictitious leads who’d be working on this project: Curopal for automation and Audient for observability.


Logging
I’ve been using Papertrail for logging and a little bit of Honeycomb.io for observability and… well, from first hand experience with my day job I know what happens to these cloud providers the minute you accidentally get even a little bit popular: suddenly they cost thousands of dollars a month and their sales team is trying to get in touch with you every day. Sometimes using actual phones, because sales people are horrifying sexual deviants who never learned that the human voice is the devil’s instrument. No sirree Bob, I’m going to run my own logs and metrics THANK YOU.
This turns out to be not an insignificant project.
As much as cloud services are fraught with salespersons and hidden expenses, I love Papertrail because:
I send logs to Papertrail, as many as I want
Papertrail makes those logs searchable
after a while, it throws them out and saves a zip to S3
that is everything
If that sounds incredibly easy, that is because it is. There’s a team of engineers there hiding all kinds of decisions about indexing and write-ahead-logs and t h r o u g h p u t for me, and I don’t have to think about any of it. LOGS GO IN. I SEARCH. PROBLEM SELVE.
As a counterpoint, the ELK Stack (or “The Elastic Stack” as it wants to be called) is the most prominent open-source logging solution by a country mile, and it demands slightly less configuration than an active nuclear reactor.
For one thing, ElasticSearch is not a log aggregation tool or solution, it’s a clunky indexing engine build atop LUCENE. Getting it to deal with logs is a bodge already.
The process of getting logs from “the myriad sources on your servers” all the way to “Kibana” is the sort of thing that will take a professional developer a full-ass week to get going.
You’ve gotta shape your logs (which are not JSON) into JSON, and then you’ve gotta decide how to INDEX that JSON so that it’s optimally searchable based on categories you haven’t even really decided yet.
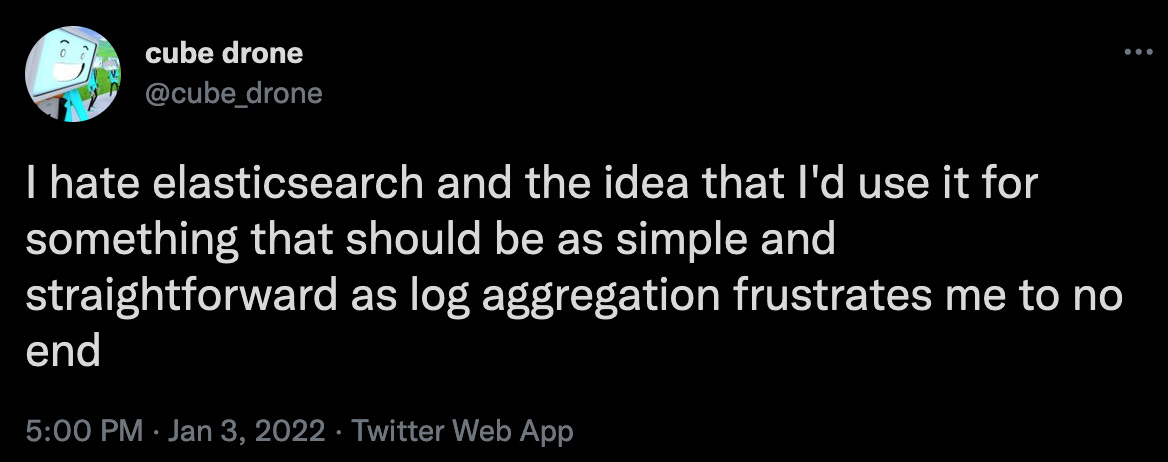
actually, this has been put a lot more eloquently by someone else:

So, when I complained about this on twitter, a coworker and a friend from a previous job helpfully appeared and recommended Grafana Loki, which is immediately 1000% better than Elasticsearch by virtue of “never making you deal with JSON”.
There’s still a lot to deal with, though. The amount of complexity that the Papertrail team are sweeping under the rug with their product is significant.
That only compounds when I get into
Metrics
Okay, again, I have a cloud service for this, StatHat, which I love.
StatHat is like Papertrail, but for stats: you give it data points, it puts them into charts for you, that is it. It’s unbelievably simple. It costs $99/mo for basically-unlimited graphs, and while that’s a fabulous deal for a company’s stats, there is no WAY I can justify that kind of bonkers expense for a personal project. $99/mo is such a weird price point, it’s, like, too expensive for small projects, and yet stupidly, vanishingly cheap for companies.
For this, there’s… well, lots and lots of options, including InfluxDB (which I’ve tried and didn’t care for), Prometheus, and VictoriaMetrics, which one of my opsy co-workers has been deploying aggressively around the office at things because it is weirdly, almost concerningly fast.
Seriously, we have single, smallish VictoriaMetrics nodes dealing with high-granularity data from large work clusters without breaking a sweat, I have no idea what kind of insane devil magic is going on in there. The most compelling theory as to how VictoriaMetrics could possibly be so fast is that it simply discards all received data and makes its own numbers up as it goes.
The docs for the product aren’t great, though. It mostly just claims to be cross-compatible with Prometheus and InfluxDB at the same time and throws up its hands as if to say “well, you know how to use Prometheus and InfluxDB, don’t you?”.
Docker, Not Kubernetes (for now)
I really like administrating a system with mostly just docker. It has more than its share of flaws, but it’s really nice to just have a whole bunch of self-contained services all nicely laid out in a row. The original dedicated server was running a lot of docker, and the new one’s going to be running a lot of docker, too.
On the other hand, I do not think that I am sufficiently foolhardy to attempt to run my own Kubernetes cluster. A LOT of stuff goes into building and maintaining a production-ready k8s cluster and I’m not convinced that it’s worth the trouble (and renting a k8s cluster is expensive you guys).
Kubernetes and proprietary cloud services are eating traditional ops: I’m certainly not going to bet my future on automation frameworks like ansible staying relevant.
Authenticating Relays
One thing I discover early on is that both Loki and VictoriaMetrics are from the new “composable, microservicey” brand of product where they don’t bother to include authentication or SSL directly in their service, so I spend some time whacking together a simple “HTTPS+Basic Auth” openresty wrapper recipe that I can sprinkle throughout my automations.
(Oh, openresty! So, uh, I’m very used to “nginx”, but openresty is an IMO slightly better fork of nginx that’s essentially identical, so I’ve been moving to a lot more of that)
And Then a Whole Bunch of Data Sources
Once Loki and Victoria are up and running, a lot of “configuring various services to send logs and metrics to the metrics server”. Because we’re running a lot of our systems out of docker, sending docker logs and metrics is an early priority, and node_exporter, cadvisor, promtail, promscrape, and rsyslog all play a big part in getting cluster logging and metrics all working together.
Grafana
Finally, all of the data sources get displayed in charts, graphs, and log traces in Grafana.
That’s the downside of this whole “hosting my own metrics” plan: I’ve always kinda hated Grafana. It’s fussy. It’s a too-powerful piece of technology that’s about as intuitive and easy to use as it can be, given that it’s trying to be a one-stop-shop interface for six dozen different things.
The final result is that everything is working: I’ve got a truly spectacular amount of logs and metrics pointed at Grafana, and now I have this powerful, arcane interface for turning those things into “some kind of useful dashboard” but that’s a whole project to itself.
Well, most of the “useful dashboard” is going to have to wait on my actually moving my various projects over to these servers - right now, I just have a lot of monitoring services very carefully monitoring other monitoring services.
![I restored in HD 4k the original "Spider-Man Pointing at Spider-Man" Template - (aka spiderman confusion meme) - [4096*3072] : r/MemeRestoration](https://substackcdn.com/image/fetch/$s_!mhcX!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fbucketeer-e05bbc84-baa3-437e-9518-adb32be77984.s3.amazonaws.com%2Fpublic%2Fimages%2F47a30ddd-3ddd-44e9-b418-a16dfa6d237a_4096x3072.jpeg "I restored in HD 4k the original "Spider-Man Pointing at Spider-Man" Template - (aka spiderman confusion meme) - [4096*3072] : r/MemeRestoration")
Okay, now to make the servers do something useful…